Hyper Estraierとは、オープンソースの全文検索システムです。
同じくオープンソースな社内SNS「SKIP」の全文検索機能では、このHyper Estraierをバックエンドとして使わせてもらっているのですが、この前、新しく環境構築をした時に、検索結果がエラく文字化けしてしまって困りました。
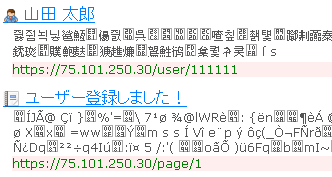
文字化けしている検索結果は、こんな具合です。
$ estcall raw http://localhost:1978/node/node1/get_doc?id=1"
上記のような感じでestcallコマンドで、直接レスポンスをみても結果は同様です。
どうやらインデックス化される時点で文字化けしてしまっているらしい。
で、検索対象のコンテンツの文字コードが識別できていないんじゃないかと思うも、、、
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
検索対象のコンテンツには上記の通り、Content-Typeが明示されています。
色々と調べた結果、HTTPのレスポンスヘッダで、、、
Content-Encoding: gzip Content-Type: text/html
コンテンツの圧縮転送をしていて、かつcharsetがついていないときに文字化けすることが判明。
SKIPでは全文検索機能用にコンテンツとアクセス制御情報等を保持しているメタ情報のみを、キャッシュとして吐いて、そこをHyper Estraierにクロールさせているのですが、キャッシュデータを配信しているWebサーバの設定を変更することで、何とか解決。
# この時使用していたlighttpdに原因があるかもしれないが。
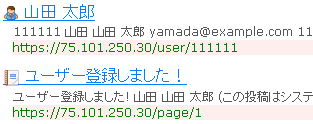
この通り。
私はキャッシュ配信にlighttpdを使っているのですが、このキャッシュ用のURL以下のみ、UTF8しか使っていないので、
mimetype.assign = ( ".html" => "text/html; charset=utf-8" )
こんな感じで無理矢理MimeTypeに設定しちゃっても正常に動きはするのですが、どーもイマイチな対応なので、とりあえずコンテンツの圧縮転送(compressディレクティブ)を無効にして、クロールの頻度を調節するようにしました。
ちゃんとした根本原因は掴めていませんが、なんとか対処。